Hay ocasiones en las que nos toca aplicar algún tipo de transformación a todos aquellos campos o columnas de un determinado tipo, como por ejemplo sería pasar a mayúsculas todo el contenido de las columnas String o hacer un cast de todos aquellos campos Float y pasarlos a Double. Este tipo de tareas suele ser engorrosas si nos toca trabajar con un set de datos muy amplio o si no sabemos aplicarlo de forma dinámica. Es por esta razón que traemos un ejemplo enfocado únicamente a la transformación dinámica de datos de tipo String pero que puede valer como referencia para implementar transformaciones sobre columnas de cualquier otro tipo de datos.
Imaginemos que tenemos que aplicar una transformación simple sobre los datos, la cual consiste en aplicar un trim (eliminación de espacios en blanco por izquierda y derecha) y pasar los datos a mayúsculas. Para ello crearemos un DataFrame tal cual lo hicimos en este artículo que a los efectos del presente simula lo que podría ser el resultado de la lectura desde una fuente de datos como pudiese ser una bases de datos relacional, una fichero en formato columnar en parquet o la lectura de un fichero de texto.
Como se puede apreciar en el siguiente apartado algunos valores poseen espacios a izquierda y derecha e incluso muestran cierta carencia de uniformidad en el formato de los datos apareciendo algunos en minúsculas otros en mayúsculas y en alguna ocasión una mezcla de ambos.
import spark.implicits._
//datos origen
val data = Seq((" Jose ", " Rodríguez ", " Torrejón de Ardoz ", " MadRID", 40, 74, 1.63, " Aries ", " Ingeniero de Sistemas "),
(" María Isabel ", " Perez ", " Torrejón de Ardoz ", "Madrid", 38, 58, 1.65, " capricornio ", " Médico "),
(" Antonio José ", " Rodríguez ", " valencia", "Valencia", 27, 60, 1.68, " Acuario", " Nutricionista "),
(" Norma ", " MaRTINEZ ", "Talavera de la Reina", "Toledo", 63, 65, 1.54, "Leo", " ChEF "),
(" Adriana ", "Peña Hernandez", " Santiago de COMPOstela ", "A Coruña", 59, 59, 1.56, " Leo ", " Economista "),
("Jesús", "Marquez ", "Alicante", "Alicante", 33, 67, 1.78, " acuario ", "Administrador"),
(" Josefina ", " Petón Marquez ", " VALENcia ", "Valencia", 25, 54, 1.60, " Sagitario ", " Administrador "))
val sourceDF = data.toDF("name", "lastname", "city", "province", "age", "weight", "height", "zodiac sign", "profession")
sourceDF.show(false)
Dinámicamente procedemos entonces a aplicar la transformación sobre todos aquellos campos de tipo String, quitando los espacios en blanco y pasando todo el contenido a mayúsculas pero exclusivamente aquellos campos cuyo tipo de dato es String
import org.apache.spark.sql.functions.{col, trim, upper}
import org.apache.spark.sql.types.{StringType}
// Se invoca la función trim y upper únicamente en aquellos campos del tipo String
val sourceDFWithTrimedValues = sourceDF.select(sourceDF.schema.fields.map(field => {
if (field.dataType == StringType) {
upper(trim(col(field.name))).as(field.name)
} else {
col(field.name)
}
}):_*)
sourceDFWithTrimedValues.show(false)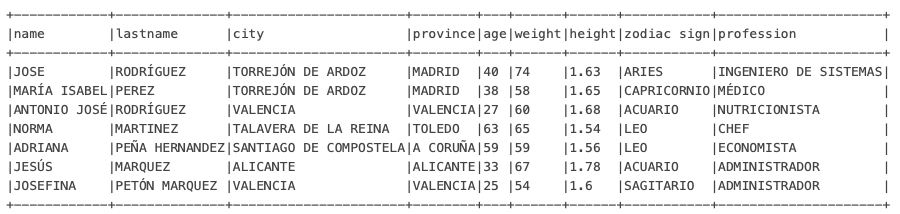
Como puedes ver todos aquellos campos que son cadenas de caracteres han sido transformados mientras que aquellos que son de un tipo numérico como son los campos «age», «weight», «height» se mantienen inalterados. Ahora dejo de vuestra parte corroborar que los cambios únicamente se aplicaron en los campos de tipo String, por ejemplo mostrando el esquema del DataFrame o ir más allá y encadenar otra transformación.
En conclusión hemos visto una forma dinámica e incluso elegante de aplicar una transformación transversal a todos los campos de un tipo de dato determinado.